
There are various situations where you’ll find yourself needing to import a sizable amount of JSON to seed a Core Data store. Sometimes you can ship this data alongside your app in the form of a pre-populated SQLite store. Other times, the data that you need to retrieve is so dynamic that shipping the data alongside the app doesn’t make sense. Or maybe the data you need to fetch is user-specific which would prevent you from pre-seeding altogether.
Regardless of why exactly you need to seed your database with remote JSON, implementing an efficient importer can be rather tricky. At Stream, we recently worked on a big overhaul for improving how the Stream SDK imports data. In this post, you will learn about best practices to build an efficient and robust data-importing strategy that can handle vast amounts of data without slowing down to a crawl.
By the end of this post, you will know and understand the following topics:
- Understanding the problems with importing data
- Determining the best import strategy for your use-case
- Optimizing fetched data for your importer
- Building your import strategy
The Problem With Importing Data
Importing data can be a challenging task regardless of the data format you’re parsing, and regardless of the store you’re importing said data to. In the case of Stream, we’re working with JSON as the data format to import, and Core Data as the store to import this data into. For that reason, this section is focussed on JSON and Core Data, but a lot of the issues described in this section apply to virtually any import scenario.
Knowing How Your Importer Performs
First and foremost, one of the trickiest things when writing a data importer is that you’re most likely developing against a data set that’s smaller than the data set you might end up importing. This makes sense because you don’t want to deal with an importer that’s so slow that you’re spending lots of time waiting for it to run just to see whether your importer works. The downside is that if you never plug in a larger dataset, you won’t know whether your importer is just as snappy in production as it is on your development machine. This problem can be exacerbated when you’re developing against a staging environment that’s sending a lot less data than your production environment.
To properly test any importer, I always recommend to run tests with datasets that are at least twice as large as you expect them to be. This might sound like an overreaction, but it makes sense. If your dataset contains user data for example, your most loyal users will be the ones with the most data. These are the users to impress with snappy performance even if they are outliers.
Once you’ve established a good data set to test your importer with, the real challenges start.
The first thing you should always do when you’re going to optimize anything in your code is establish a baseline. Two tools that you can use to establish a baseline when importing data into a Core Data store like Stream does are Instruments, and Core Data’s logging capabilities.
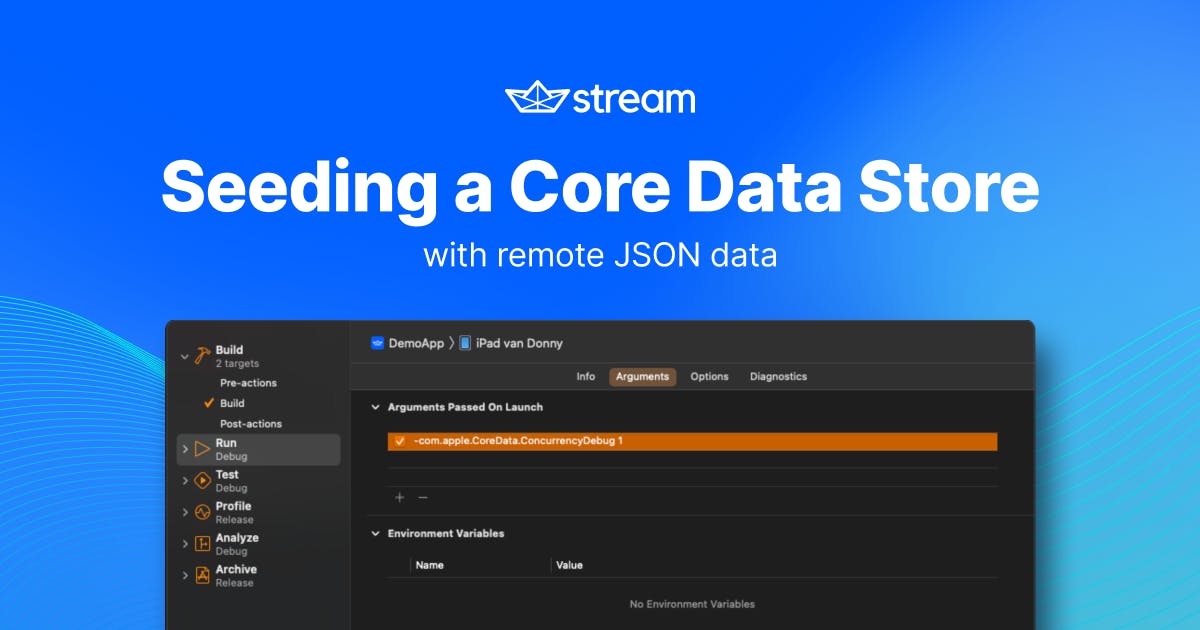
To enable Core Data’s logging, you should add the following argument to your app’s debug scheme:
com.apple.CoreData.SQLDebug 1When added, your scheme should look as follows:

Adding this launch argument will instruct Core Data to log every query it executes on the underlying SQLite store to the console in Xcode. This is extremely useful if you want to gain a quick sense of what’s going on behind the scenes.
The second tool you should always use when profiling performance is Instruments. In this case, there are two Instruments to look at:
- Time Profiler - this instrument is useful to pinpoint which code in your app might be slower than you thought.
- Core Data - this instrument is useful to gain more insights into your Core Data fetch requests, your saves, and how long everything takes.
Once you start profiling your code, it’s likely that you’ll find your import logic isn’t as snappy as you’d like it to be. Let’s take a look at some common issues that you might encounter when implementing an importer of your own.
Limiting the Number of Database Interactions
Whether you’re running plain SQLite queries, Core Data fetch requests, network calls, or any other call or query to read data from some data source, it’s likely that these calls are not cheap. A common pattern in lots of applications is to have a “find or insert” method in place for every object that should be imported.
For example, consider a JSON payload that holds conversations. These conversations will have messages, participants, and more. Each message will have a sender and a receiver, and other data associated with it. Take a look at the sample payload below to get an idea of the shape of the data that Stream handles.
1234567891011121314151617181920212223242526272829303132333435363738394041424344454647484950515253{ "type": "channel.updated", "cid": "messaging:general", "channel_id": "general", "channel_type": "messaging", "channel": { "id": "general", "type": "messaging", "cid": "messaging:general", "created_at": "2022-03-28T18:09:34.870509Z", "updated_at": "2022-03-28T18:09:34.87051Z", "created_by": { "id": "count_dooku", "role": "user", "created_at": "2020-12-07T11:37:39.487938Z", "updated_at": "2022-02-03T11:36:17.626315Z", "last_active": "2022-03-28T18:11:22.920214284Z", "banned": false, "online": true, "name": "Count Dooku", "image": "https://vignette.wikia.nocookie.net/starwars/images/b/b8/Dooku_Headshot.jpg", "birthland": "Serenno", "extraData": {}, "image_url": "https://vignette.wikia.nocookie.net/starwars/images/b/b8/Dooku_Headshot.jpg" }, "frozen": false, "disabled": false, "members": [ { "user_id": "count_dooku", "user": { "id": "count_dooku", "role": "user", "created_at": "2020-12-07T11:37:39.487938Z", "updated_at": "2022-02-03T11:36:17.626315Z", "last_active": "2022-03-28T18:11:22.920214284Z", "banned": false, "online": true, "image_url": "https://vignette.wikia.nocookie.net/starwars/images/b/b8/Dooku_Headshot.jpg", "name": "Count Dooku", "image": "https://vignette.wikia.nocookie.net/starwars/images/b/b8/Dooku_Headshot.jpg", "birthland": "Serenno", "extraData": {} }, "created_at": "2022-03-28T18:09:34.877085Z", "updated_at": "2022-03-28T18:09:34.877085Z", "banned": false, "shadow_banned": false, "role": "owner", "channel_role": "channel_member" } // and more…
This snippet isn't a complete representation of a response that’s imported by the Stream SDK. Again, this snippet is supposed to give you some idea of what we’re working with.
If you look at this JSON, there are a bunch of entities that we have to import:
- Channel
- Message
- Attachment
- User
- And, to be honest, a bunch more that aren’t in this example
It’s tempting to loop over this JSON, and for each entity ask the database for an existing entry, or to create a new one. It’s also tempting to immediately save the record you just created (or update) so that subsequent fetches will return an existing record rather than creating a new one that would be a duplicate of the one you just created.
Some database engines allow you to omit the “find” step completely and will do something called an UPSERT when you attempt to insert data that has a duplicate unique key (an identifier could be a unique key for example). This is nice, because then you can just create a new record every time, save it, and know that the existing record is inserted, or updated if it already exists.
Unfortunately, Core Data has an UPSERT mechanism but it doesn’t work properly with to-many relationships. Essentially, when Core Data tries to do an UPSERT when saving data, it will completely wipe out the to-many relationship rather than using the relationships as defined by the up-to-date record. This means that apps that leverage Core Data are typically stuck using a “find or insert” method instead.
On the other hand, we already knew that database reads are expensive. Unfortunately, database writes aren’t cheap either. This means that even if Core Data had a working UPSERT mechanism, it would most likely not be feasible to rely on it because it would require us to save each individual record right after creating it. As you can imagine, a large import would result in thousands of save operations.
So at this point we’ve established that database reads are expensive, and so are database writes. You can make tremendous improvements to your importer by flushing all of your updates to the database in one transaction. In Core Data this means that you’d be running your entire import, and you only save your managed object context at the end of the entire import operation. A single huge database transaction is much faster than doing thousands of small, quick, queries. This is also true for Core Data.
To limit the amount of fetching you have to do in your importer, you can do one of two things:
- Populate a cache as you go
- Prewarm a cache with all objects you might need
We’ll explore the former option right now, and the latter option will be explained more in the next subsection.
Populating Your Cache as You Go
The easiest way to limit the number of fetches you do while importing is to cache the objects that you have fetched already. This means that you’ll only do one fetch for each unique record in the data you’re importing. This approach works incredibly well for datasets that contain a lot of repeated data, and you can imagine that Stream deals with lots of repeated data mostly in the users department. A conversation between two users can have hundreds of messages and each message points to multiple users. If you cache all users as you encounter them, that means that you only load each user from the persistent store once, saving you lots of trips to the store.
A cache that implements this can be implemented as a dictionary that’s checked any time you call your “find or replace” method.
Instead of doing the following:
- Check database for existing record
- Create a new one if no record exists
You would do the following:
- Check cache for existing record
- If not, check if record exists in the database
- Create a new record if no record exists
It’s a small change, but performing a lookup in a dictionary is much cheaper than going to the underlying store.
To give you an idea, running an import of a moderately large Stream payload without any caching takes more than seven seconds and involves 11,582 fetch requests. Running the same import with caching enabled takes about 3.5 seconds and involves 3,183 fetch requests. That’s a huge difference, and it clearly shows that database interactions can be a real bottleneck when executing large imports.
Once you’ve optimized the number of fetch requests needed to perform your import, it’s worthwhile to take a look at the data you’re importing to see if there’s anything to be gained from changing the way you interact with this data.
Optimizing Fetched Data for Your Importer
While there’s plenty that you can do to optimize the way you import data, an often and easily overlooked aspect of writing an importer is that it’s always good to take a close look at what you’re importing exactly.
If you take a look at the JSON snippet that you saw earlier, you’ll notice that there’s lots of potential for repeated data in there. For example, user objects are duplicated in the JSON many times. This means that while parsing this data, you’re processing the same user object multiple times. In other words, each user object will be:
- Fetched from the database once
- Read from the cache many times
- Updated with the same “new” data many times
These points might not sound like they’re that big of a deal, but imagine that we have a response with 100 unique user objects that are on average repeated 20 times each. The result would be that we make 100 database queries, read from cache about 1,900 times, and that we assign new values to each user’s properties 19 times more than needed.
With this in mind, it makes sense to do some extra processing on the decoded JSON data.
For example, once the data is decoded you can iterate through its contents and collect all unique user objects that you’re working with. This will allow you to do two things:
- Use the user ids to prewarm a cache with all user objects that exist in the JSON data.
- Only process and update the user objects once because you know that a given user will always have the same data no matter how often the user exists in the JSON.
If these optimizations are implemented, we can perform a single database query to fetch all 100 unique users from the scenario that I outlined earlier. We’ll update each user once in an ideal situation, and we’ll still read the user from cache as many times as needed so we can associate the user objects with the relevant channels and messages.
We’ll cover how to do all this later. For now, we’re focusing on understanding why it’s important to do extra processing on our data.
As mentioned before, Stream deals with large amounts of data so it’s essential that Stream optimizes data imports as much as possible. Now that we know some of the bottlenecks that might exist when importing data, let’s take a look at how you can determine the best strategy for your use case.
Determining the Best Import Strategy for Your Use-Case
Even when it sounds like importing data has a handful of universal issues, the best way to tackle these issues isn’t the same for every app. As is often the case in programming, the best solution to the problem of importing data depends on the constraints and type of data you’re working with.
In the previous section, we focused on the problems Stream deals with, and I briefly outlined how these problems are solved in the Stream SDK. However, this solution might not be a good solution for your use case. To determine the best solution for your situation, there are a couple of things to keep an eye on:
- If you already have an importer, what is its performance like?
- How much data are you importing in an exaggerated case?
- What does your data look like?
In all cases it’s beneficial to implement a simple caching strategy to avoid having to perform lots of fetches while importing data. However, if you’re importing to a store that has good support for UPSERT-ing data, this might not be as essential because you can simply attempt to persist duplicate data and know that this data will be updated in the underlying database automatically.
Post-processing your data is really only relevant when:
- You’re having performance issues.
- Your data has lots of repeated data.
The act of post-processing your data typically makes for a less flexible importer, and as you’ll find out in the next section, your code will become harder to read and maintain. When this is the result of solving a real performance issue, it’s a worthwhile trade-off. On the other hand if you’re doing this “just in case”, the extra complexity in your code often isn’t worth it.
Even if you have a performance issue, you have to assess whether post-processing your JSON will result in a significant enough performance benefit. If you hardly have any repeated data, it might make sense to forego post-processing and/or your cache entirely.
Or if your importer only runs on your app’s first launch, it makes sense to simply skip any fetches from your persistent store because you know for a fact that the store will still be empty when your importer starts running.
There is no one-size-fits-all solution for a complex problem like importing data, so it’s important to keep your specific situation, use-case, and requirements in mind when determining how you want to write your data importer.
In the next section, we’ll explore the steps that were taken in the Stream SDK to improve performance of data imports, and we’ll explore some possible future solutions that could further enhance Stream’s data imports.
Building Stream’s Import Strategy
Once you’ve determined your import strategy, you can start building your implementation. For Stream, we’ve gone with an import strategy that will gradually build up a cache of the objects that we’ve fetched so that we don’t fetch the same object twice.
Rather than focusing on how the JSON we’re importing is obtained, I want to focus on the more interesting part of actually performing the import to Core Data.
In the Stream SDK, there are several places that might start a data import. We know that we should only have a single import active at a time, and that an import will always run on a background managed object context. Using a background managed object allows us to run the data import without worrying about whether the view will prematurely update itself or not. The view will only update once the background object saves and the managed object context that’s used by our views pulls in the changes from the background context.
We’ve opted to make the process of merging changes into the view context automatic by setting our view context’s automaticallyMergesChangesFromParent property to true.
The core or Stream’s data import is encapsulated in code that looks a little bit as follows:
123456789101112131415161718func write(_ actions: @escaping (DatabaseSession) throws -> Void, completion: @escaping (Error?) -> Void) { writableContext.perform { do { FetchCache.clear() try actions(self.writableContext) FetchCache.clear() if self.writableContext.hasChanges { try self.writableContext.save() } completion(nil) } catch { FetchCache.clear() completion(error) } } }
This code is slightly simplified, but the core of what you should note is that we make sure that we always start and end with a cleared object cache. The reason for this is that we don’t actively maintain the cache outside of imports. This means that certain objects might no longer exist or be relevant; we’ve found that we got better results when clearing the cache first than when we didn’t clear the cache.
The most interesting part of the snippet above is the FetchCache so let’s take a look at its implementation next.
1234567891011121314151617181920212223242526272829303132333435class FetchCache { fileprivate static let shared = FetchCache() private let queue = DispatchQueue(label: "io.stream.com.fetch-cache", qos: .userInitiated, attributes: .concurrent) private var cache = [NSFetchRequest<NSFetchRequestResult>: [NSManagedObjectID]]() fileprivate func set<T>(_ request: NSFetchRequest<T>, objectIds: [NSManagedObjectID]) where T: NSFetchRequestResult { guard let request = request as? NSFetchRequest<NSFetchRequestResult> else { return } queue.async(flags: .barrier) { self.cache[request] = objectIds } } fileprivate func get<T>(_ request: NSFetchRequest<T>) -> [NSManagedObjectID]? where T: NSFetchRequestResult { guard let request = request as? NSFetchRequest<NSFetchRequestResult> else { return nil } var objectIDs: [NSManagedObjectID]? queue.sync { objectIDs = cache[request] } return objectIDs } static func clear() { Self.shared.clear() } private func clear() { queue.async(flags: .barrier) { self.cache.removeAll() } } }
The code above is the complete implementation for our cache. Not too bad, right? It’s a simple cache that does a great job of caching objects in a way that makes sense for Stream. Because every fetch in the codebase starts as an NSFetchRequest, we can use the fetch request instance as a key for our dictionary. Fetch requests that are configured in the same way produce the same hash value, which means that we can safely use a fetch request as our dictionary key.
Note that instead of caching references to managed objects directly, we cache NSManagedObjectID instances. These managed object ids can be used to retrieve managed objects safely across threads, and if an object has been loaded into a managed object context already, we won’t go to the underlying store. This is quite different from a fetch request because fetch requests always drop down to the underlying store which is less efficient.
As we iterate through our already parsed JSON, each JSON object will be converted to a managed object using a method that looks a bit as follows:
1234567func saveChannel( payload: ChannelDetailPayload, query: ChannelListQuery? ) throws -> ChannelDTO { let dto = ChannelDTO.loadOrCreate(cid: payload.cid, context: self) // ... assign values from payload to dto }
This code shouldn’t look all that surprising. Every managed object in the Stream codebase has a loadOrCreate method defined. This method is used to attempt to fetch an existing managed object for a given id from our payload, or to insert a new object.
Let’s take a look at an example of a loadOrCreate method:
12345678910static func loadOrCreate(cid: ChannelId, context: NSManagedObjectContext) -> ChannelDTO { let request = fetchRequest(for: cid) if let existing = load(by: request, context: context).first { return existing } let new = NSEntityDescription.insertNewObject(into: context, for: request) new.cid = cid.rawValue return new }
In the loadOrCreate method, we create a new fetch request and call load(by:context:) with this fetch request. The load(by:context:) method is defined in an extension on NSManagedObject and it looks as follows:
12345678static func load<T: NSManagedObject>(by request: NSFetchRequest<T>, context: NSManagedObjectContext) -> [T] { request.entity = NSEntityDescription.entity(forEntityName: T.entityName, in: context)! do { return try context.fetch(request, using: FetchCache.shared) } catch { return [] } }
Since this method really doesn’t do much on its own, let’s move one level deeper to look at the fetch(_:using:) method that we call on context:
1234567891011func fetch<T>(_ request: NSFetchRequest<T>, using cache: FetchCache) throws -> [T] where T: NSFetchRequestResult { if let objectIds = cache.get(request) { return try objectIds.compactMap { try existingObject(with: $0) as? T } } // We haven't `fetch`ed the request yet let objects = try fetch(request) let objectIds = objects.compactMap { ($0 as? NSManagedObject)?.objectID } cache.set(request, objectIds: objectIds) return objects }
At this point we’re finally actually using our cache. Since this method is generic, we can call it for any managed object that we’d like. So you can imagine that for every loadOrCreate method that we define on DTO objects there will be a call to this specific fetch(_:using:) implementation.
If a given managed object id exists in the cache, we try to load it using existingObject(with:). This method returns an instance of NSManagedObject so we have to cast our result to T to see if the found object is, in fact, of the correct type (it should be, managed object ids aren’t duplicated between entities).
And of course if an object isn’t found, we add its managed object id to the cache.
This is really all there is to building an import that is much more efficient than it would be if no caching would take place. There’s some for improvement because the data that we import into the Stream SDK has some duplication, which means that we could pick apart our source data and prewarm the cache for even better performance.
However, for now, we’re very happy with the performance we’ve managed to achieve with this simple caching strategy. To summarize, here’s how the cache and code you just saw works:
- JSON is decoded into model objects
- For each model object, we attempt to load or create a DTO
- The DTO creates a fetch request and calls a generic load method
- This generic load method then calls a fetch method on the managed object context, passing it a cache that should be used.
- If an appropriate object id was found in the cache, it’s used to grab a managed object. If not, a new managed object is created and its id is added to the cache.
As mentioned before, not including this cache would result in lots and lots of trips to the underlying store. Adding a cache has dropped the number of fetch requests that needed to be executed by about 72%. This sped up the importer by about 51%. That’s a huge improvement and we’re eager to continue working on improving the import strategy even more.
In Summary
Hopefully by now you have a good perspective on what a good data import strategy for a Core Data store looks like. As always, the most important aspect of optimizations is to make sure that the optimizations you’re making are needed (they should solve a problem you have), and that it’s important to continuously measure whether your optimizations work, and are worth the trade-off you might be making in terms of readability.
In this post, you saw how you can pick apart a JSON file that contains lots of repeating data to limit the number of fetches and updates that are done in Core Data. You saw that doing this makes your code a little less trivial, but the performance gains are worth the trade-off. We were able to vastly increase the speed of the import at Stream by implementing the solutions outlined in this article.
Even though every situation is unique, hopefully this post has given you an idea of how you might tackle performance improvements on your own data importers even if the solution that’s best for you isn’t exactly the same as the one that worked for Stream.