
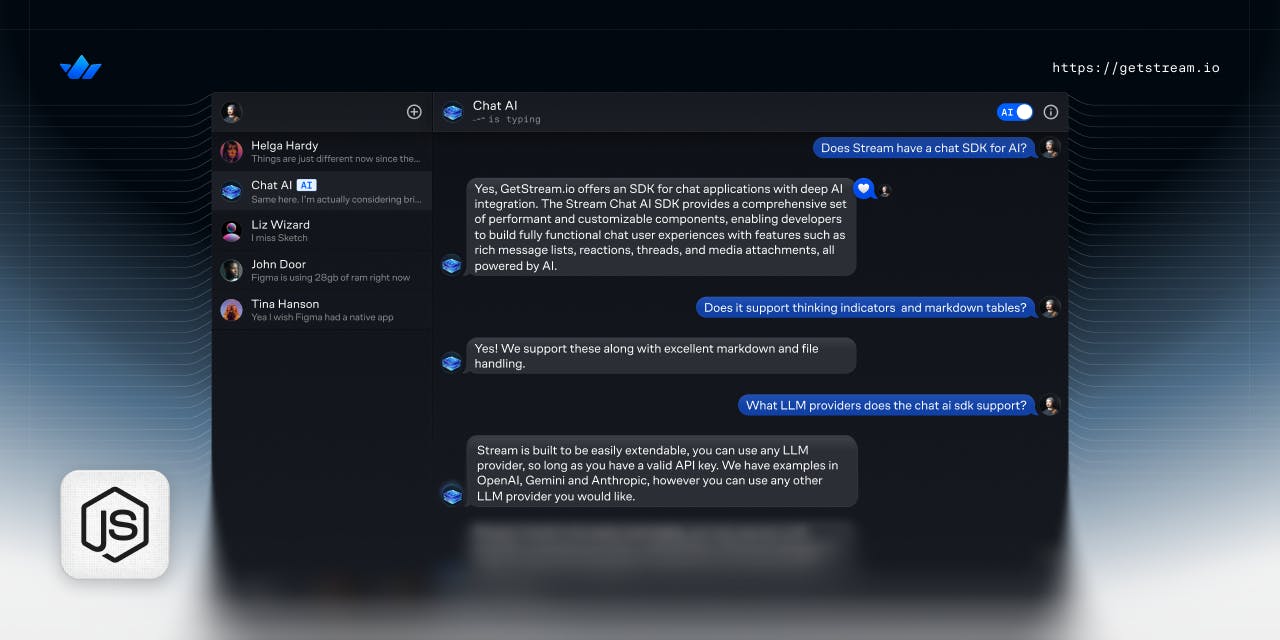
In this post, we will see how we can build a NodeJS server that will allow frontend chat SDKs to start and stop an assistant for a given channel in Stream Chat.
Building polished AI assistants can be challenging. Features like streaming responses, table components, and code generation require complex implementation across SDKs and the backend.
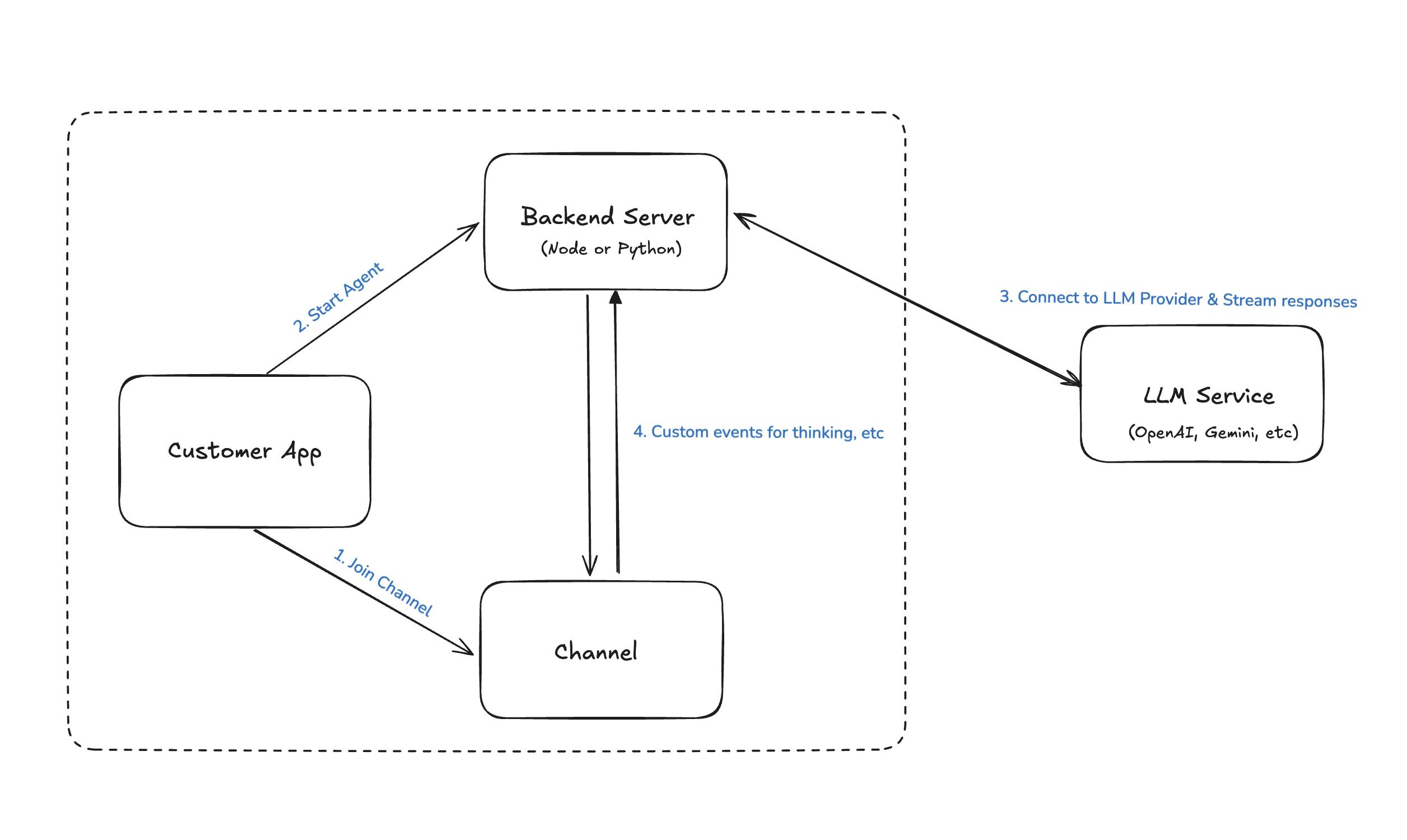
To ease this, we’ve developed a universal solution that connects our Chat API to external LLM providers via a single backend server (NodeJS or Python), simplifying assistant management and integration.
When started, the assistant will join the channel, listen to new messages from the chat participants, and send them to an LLM to get AI-generated responses.
Let’s see how we can build this. You can find the complete project that you can run locally here.
Creating the NodeJS App
To follow along, ensure you have Node.js installed on your machine. You can download it from the official website. npm (Node Package Manager) comes bundled with Node.js. At the time of writing, a node version of 22 was used.
First, let’s create a new folder and initialize Node.
123mkdir node-js-ai cd node-js-ai npm init -y
The last command generates a package.json file with default settings.
Adding the Dependencies
Let’s now add all the dependencies that we will need for our project.
npm install stream-chat openai @anthropic-ai/sdk express cors dotenvLet’s check all the dependencies in more detail.
As this project is written in TypeScript, we need to add a dev dependency to TypeScript as well
npm install –save-dev typescriptStreamChat’s NodeJS SDK, enables real-time chat features, essential for building modern, scalable messaging functionalities. We will use it to listen to all the messages in the channel, and send those to LLMs for AI generated responses.
The dotenv package helps manage environment variables by loading them from a .env file, making it easier to securely store sensitive data like API keys or configuration details without hardcoding them into the app.
The OpenAI SDK allows you to interact with OpenAI’s APIs, such as GPT models, for building AI-powered functionalities like text generation, summarization, or code assistance.
The Anthropic SDK connects to Anthropic’s AI models like Claude, enabling advanced conversational AI capabilities for use cases such as customer support or knowledge retrieval.
Express is a minimal Node.js framework used to build RESTful APIs or web applications. It provides robust tools for routing and middleware, making backend development straightforward.
CORS (Cross-Origin Resource Sharing) middleware enables secure communication between your server and frontend applications hosted on different origins, ensuring seamless API access across domains.
With all those dependencies installed, let’s now update the “scripts” part of the package.json, where we will set up how to start the node.js server:
1234567891011121314{ "name": "@stream-io/ai-nodejs-server", "version": "1.0.0", "description": "", "main": "dist/index.js", "type": "commonjs", "engines": { "node": ">=20" }, "scripts": { "start": "tsc && node dist/index.js", "test": "echo \"Error: no test specified\" && exit 1" }, // Other entries, such as dependencies
This will allow us to run the server with the command npm start. This command will also convert the TypeScript code to regular JavaScript that Node can execute.
Let’s now add some simple TypeScript configuration file (tsconfig.json) to the root directory of our project:
1234567891011{ "compilerOptions": { "target": "es2020", "module": "CommonJS", "moduleResolution": "Node", "sourceMap": true, "outDir": "./dist", "strict": true, "skipLibCheck": true } }
Now, we have all we need to run our server. But before we do that, let’s add some code.
Creating the Index.ts File
First, let’s create the index.ts file, which will provide the two endpoints for starting and stopping the AI agents.
123456789101112131415161718192021222324252627282930313233343536373839404142434445464748495051525354555657585960616263646566676869707172737475767778798081828384858687888990919293949596979899100101102103104105106107108109110111112113114115116117118119120121122123124125126127128129130131132133134135136137138139140141142143144145import 'dotenv/config'; import express from 'express'; import cors from 'cors'; import { AIAgent } from './agents/types'; import { createAgent } from './agents/createAgent'; import { apiKey, serverClient } from './serverClient'; const app = express(); app.use(express.json()); app.use(cors({ origin: '*' })); // Map to store the AI Agent instances // [cid: string]: AI Agent const aiAgentCache = new Map<string, AIAgent>(); const pendingAiAgents = new Set<string>(); const inactivityThreshold = 5 * 60 * 1000; setInterval(async () => { const now = Date.now(); for (const [userId, aiAgent] of aiAgentCache) { if (now - aiAgent.getLastInteraction() > inactivityThreshold) { console.log(`Disposing AI Agent due to inactivity: ${userId}`); await disposeAiAgent(aiAgent, userId); aiAgentCache.delete(userId); } } }, 5000); app.get('/', (req, res) => { res.json({ message: 'GetStream AI Server is running', apiKey: apiKey, activeAgents: aiAgentCache.size, }); }); /** * Handle the request to start the AI Agent */ app.post('/start-ai-agent', async (req, res) => { const { channel_id, channel_type = 'messaging', platform = 'anthropic', } = req.body; // Simple validation if (!channel_id) { res.status(400).json({ error: 'Missing required fields' }); return; } let channel_id_updated = channel_id; if (channel_id.includes(':')) { const parts = channel_id.split(':'); if (parts.length > 1) { channel_id_updated = parts[1]; } } const user_id = `ai-bot-${channel_id_updated.replace(/!/g, '')}`; try { if (!aiAgentCache.has(user_id) && !pendingAiAgents.has(user_id)) { pendingAiAgents.add(user_id); await serverClient.upsertUser({ id: user_id, name: 'AI Bot', role: 'admin', }); const channel = serverClient.channel(channel_type, channel_id_updated); try { await channel.addMembers([user_id]); } catch (error) { console.error('Failed to add members to channel', error); } await channel.watch(); const agent = await createAgent( user_id, platform, channel_type, channel_id_updated, ); await agent.init(); if (aiAgentCache.has(user_id)) { await agent.dispose(); } else { aiAgentCache.set(user_id, agent); } } else { console.log(`AI Agent ${user_id} already started`); } res.json({ message: 'AI Agent started', data: [] }); } catch (error) { const errorMessage = (error as Error).message; console.error('Failed to start AI Agent', errorMessage); res .status(500) .json({ error: 'Failed to start AI Agent', reason: errorMessage }); } finally { pendingAiAgents.delete(user_id); } }); /** * Handle the request to stop the AI Agent */ app.post('/stop-ai-agent', async (req, res) => { const { channel_id } = req.body; try { const userId = `ai-bot-${channel_id.replace(/!/g, '')}`; const aiAgent = aiAgentCache.get(userId); if (aiAgent) { await disposeAiAgent(aiAgent, userId); aiAgentCache.delete(userId); } res.json({ message: 'AI Agent stopped', data: [] }); } catch (error) { const errorMessage = (error as Error).message; console.error('Failed to stop AI Agent', errorMessage); res .status(500) .json({ error: 'Failed to stop AI Agent', reason: errorMessage }); } }); async function disposeAiAgent(aiAgent: AIAgent, userId: string) { await aiAgent.dispose(); const channel = serverClient.channel( aiAgent.channel.type, aiAgent.channel.id, ); await channel.removeMembers([userId]); } // Start the Express server const port = process.env.PORT || 3000; app.listen(port, () => { console.log(`Server is running on http://localhost:${port}`); });
When start-ai-agent endpoint is called the following happens:
- A user with id
ai-bot-{channel-id}is created using an admin role. You can also create a specific role if needed, as long as it has the required permissions to join a channel, watch it and read messages. - We have a cache in place (
aiAgentCache) to only allow one agent per channel. - The bot establishes a WS connection, joins the provided channel and starts watching it.
- Depending on the “platform” parameter in the request, an Anthropic or OpenAI agent is started.
When the client doesn’t need the agent anymore, it should stop it, by calling the /stop-ai-agent endpoint. This will disconnect the user and stop watching the channel.
LLM Integration
In this step, we will look into the Anthropic LLM integration, that will generate AI responses based on the intercepted messages.
The OpenAI implementation is very similar, and will not be covered in this post. If you are interested in it, feel free to check it here.
Let’s create a new file, called AnthropicAgent.ts and add the following code.
123456789101112131415161718192021222324252627282930313233343536373839404142434445464748495051525354555657585960616263646566676869707172737475767778798081828384858687888990919293949596979899100101import Anthropic from '@anthropic-ai/sdk'; import { AnthropicResponseHandler } from './AnthropicResponseHandler'; import type { MessageParam } from '@anthropic-ai/sdk/src/resources/messages'; import type { Channel, DefaultGenerics, Event, StreamChat } from 'stream-chat'; import type { AIAgent } from '../types'; export class AnthropicAgent implements AIAgent { private anthropic?: Anthropic; private handlers: AnthropicResponseHandler[] = []; private lastInteractionTs = Date.now(); constructor( readonly chatClient: StreamChat, readonly channel: Channel, ) {} dispose = async () => { this.chatClient.off('message.new', this.handleMessage); await this.chatClient.disconnectUser(); this.handlers.forEach((handler) => handler.dispose()); this.handlers = []; }; getLastInteraction = (): number => this.lastInteractionTs; init = async () => { const apiKey = process.env.ANTHROPIC_API_KEY as string | undefined; if (!apiKey) { throw new Error('Anthropic API key is required'); } this.anthropic = new Anthropic({ apiKey }); this.chatClient.on('message.new', this.handleMessage); }; private handleMessage = async (e: Event<DefaultGenerics>) => { if (!this.anthropic) { console.error('Anthropic SDK is not initialized'); return; } if (!e.message || e.message.ai_generated) { console.log('Skip handling ai generated message'); return; } const message = e.message.text; if (!message) return; this.lastInteractionTs = Date.now(); const messages = this.channel.state.messages .slice(-5) .filter((msg) => msg.text && msg.text.trim() !== '') .map<MessageParam>((message) => ({ role: message.user?.id.startsWith('ai-bot') ? 'assistant' : 'user', content: message.text || '', })); if (e.message.parent_id !== undefined) { messages.push({ role: 'user', content: message, }); } const anthropicStream = await this.anthropic.messages.create({ max_tokens: 1024, messages, model: 'claude-3-5-sonnet-20241022', stream: true, }); const { message: channelMessage } = await this.channel.sendMessage({ text: '', ai_generated: true, }); try { await this.channel.sendEvent({ type: 'ai_indicator.update', ai_state: 'AI_STATE_THINKING', message_id: channelMessage.id, }); } catch (error) { console.error('Failed to send ai indicator update', error); } await new Promise((resolve) => setTimeout(resolve, 750)); const handler = new AnthropicResponseHandler( anthropicStream, this.chatClient, this.channel, channelMessage, ); void handler.run(); this.handlers.push(handler); }; }
In the code above, we’re defining the handleMessage method, which does the following:
- on the new message event, the bot starts talking to the Anthropic API.
- a new empty message is created and a new event called
ai_indicator.updatewith a state value of “AI_STATE_THINKING” is sent to the watchers. - The message has a custom data field called
ai_generatedwith the value of true, to tell the clients it’s AI generated. The sender is the AI Bot from the backend. - We start a
AnthropicResponseHandler(we will define that next), that will listen to the streaming events from the LLM.
The implementation of the AnthropicResponseHandler looks like this:
1234567891011121314151617181920212223242526272829303132333435363738394041424344454647484950515253545556575859606162636465666768697071727374757677787980818283848586878889909192939495969798import Anthropic from '@anthropic-ai/sdk'; import type { Stream } from '@anthropic-ai/sdk/streaming'; import type { RawMessageStreamEvent } from '@anthropic-ai/sdk/resources/messages'; import type { Channel, MessageResponse, StreamChat } from 'stream-chat'; export class AnthropicResponseHandler { private message_text = ''; private chunk_counter = 0; constructor( private readonly anthropicStream: Stream<RawMessageStreamEvent>, private readonly chatClient: StreamChat, private readonly channel: Channel, private readonly message: MessageResponse, ) { this.chatClient.on('ai_indicator.stop', this.handleStopGenerating); } run = async () => { try { for await (const messageStreamEvent of this.anthropicStream) { await this.handle(messageStreamEvent); } } catch (error) { console.error('Error handling message stream event', error); await this.channel.sendEvent({ type: 'ai_indicator.update', ai_state: 'AI_STATE_ERROR', message_id: this.message.id, }); } }; dispose = () => { this.chatClient.off('ai_indicator.stop', this.handleStopGenerating); }; private handleStopGenerating = async () => { console.log('Stop generating'); if (!this.anthropicStream) { console.log('Anthropic not initialized'); return; } this.anthropicStream.controller.abort(); await this.chatClient.partialUpdateMessage(this.message.id, { set: { generating: false }, }); await this.channel.sendEvent({ type: 'ai_indicator.clear', message_id: this.message.id, }); }; private handle = async ( messageStreamEvent: Anthropic.Messages.RawMessageStreamEvent, ) => { switch (messageStreamEvent.type) { case 'content_block_start': await this.channel.sendEvent({ type: 'ai_indicator.update', ai_state: 'AI_STATE_GENERATING', message_id: this.message.id, }); break; case 'content_block_delta': if (messageStreamEvent.delta.type !== 'text_delta') break; this.message_text += messageStreamEvent.delta.text; this.chunk_counter++; if ( this.chunk_counter % 20 === 0 || (this.chunk_counter < 8 && this.chunk_counter % 2 !== 0) ) { try { await this.chatClient.partialUpdateMessage(this.message.id, { set: { text: this.message_text, generating: true }, }); } catch (error) { console.error('Error updating message', error); } } break; case 'message_delta': await this.chatClient.partialUpdateMessage(this.message.id, { set: { text: this.message_text, generating: false }, }); case 'message_stop': await new Promise((resolve) => setTimeout(resolve, 500)); await this.chatClient.partialUpdateMessage(this.message.id, { set: { text: this.message_text, generating: false }, }); await this.channel.sendEvent({ type: 'ai_indicator.clear', message_id: this.message.id, }); break; } }; }
In the handle method, we are listening to the different streaming events coming from Anthropic. We update the message text, and send events based on the state of the LLM.
- On the “content_block_start” event, we send an event that we are starting the generation.
- On the “content_block_delta” event, we construct the message text, and on every 20th chunk we update the message text.
- On the “message_delta” event, we update the message with the text we have.
- On the “message_stop” event, we are sending an event to clear the AI indicator.
We also expose a handleStopGenerating method that listens to events that stop the generation.
You can check the full implementation, along with the helper methods here.
Setting Up the .env File
Before we run the project, we need to set up the API keys of the services that we’re going to use.
There's a .env.example that you can use as a template. You should provide values for the following keys in your .env file.
12345ANTHROPIC_API_KEY=insert_your_key STREAM_API_KEY=insert_your_key STREAM_API_SECRET=insert_your_secret OPENAI_API_KEY=insert_your_key OPENWEATHER_API_KEY=insert_your_key
You can provide a key for either ANTHROPIC_API_KEY or OPENAI_API_KEY, depending on which one you would use. The OPENWEATHER_API_KEY is optional, in case you want to use the function calling example with OpenAI.
Running the Project
You can run the project with the following command:
123npm start # alternatively, you can use # PORT=3001 npm start
The server will start listening on http://localhost:3000. Check our SDK tutorials to see how to do the client integration with this server.
Conclusion
In this post, we covered the server-side integration of Stream chat with popular LLMs such as Anthropic and OpenAI.
Using this template, developers can either use our backend implementation directly with Anthropic and OpenAI or extend our server to support other LLM providers such as Gemini or xAI's Grok.
Regardless of which provider you choose, using a combination of streaming responses paired with Stream's AI events, developers can quickly bring powerful AI features to their application and atomically benefit from our rich UI components across React, React Native, Flutter, Jetpack Compose and Swift UI.
To learn more about our AI capabilities, visit our AI landing page or create a free Stream account to get started building with chat and AI!