

Content warning: This article contains some NSFW Hungarian and Korean words and phrases.
Did you know for the sitcom Mork and Mindy, the production team needed censors who knew four languages just to keep up with Robin Williams' sneaky swearing attempts?
That was in the seventies, but today’s content moderators have the same problem, writ larger. It’s not just a single comic’s profanity online moderators have to deal with, but thousands of individuals speaking hundreds of languages. If you are an English speaker, how do you know that two people conversing in Hungarian, Urdu, or Swahili on your platform are keeping it clean or breaking community guidelines?
By using AI. This is an ideal use case for advanced large language models (LLMs) trained on millions of words in most languages. They can immediately flag words and phrases across these languages that you might not want to share in your chats or streams.
Stream’s Moderation API already uses AI, but here, we will build our own to better understand how this works and show you how you can build this into your own applications. We’ll end up with a situation like this:
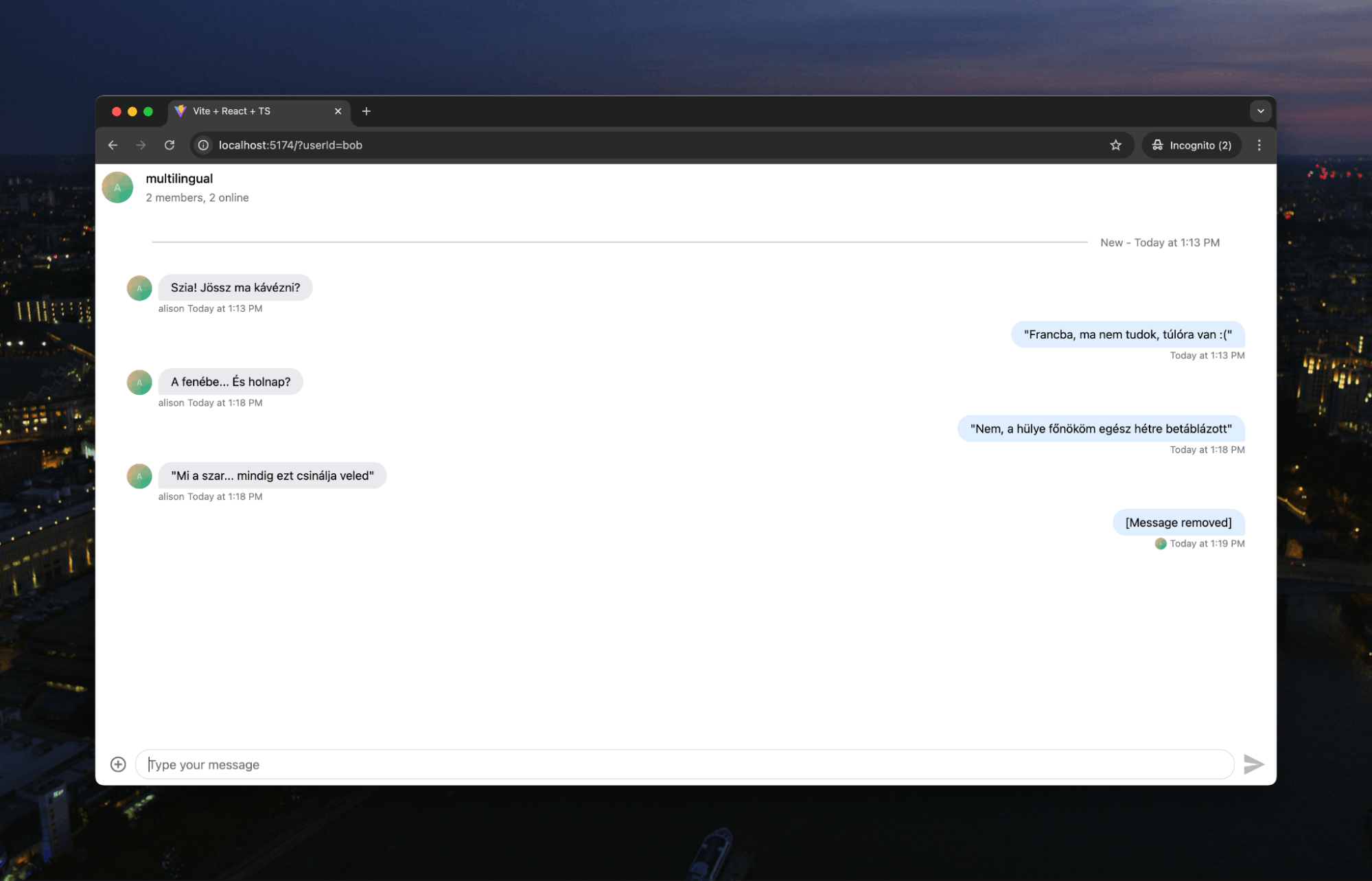
Apologies to our Hungarian readers for the light profanity in this message, but Bob’s following message was worse. Let’s look at how we stopped it.
Intercepting Our Messages
The front end of our Stream app will be based on the base Stream React tutorial app. We first need to intercept each message from users and pass them to an LLM for analysis. To do that, we’re going to create a handleSubmit function that we can call from our Stream client:
123456789101112131415161718192021222324252627282930313233343536// Add message handler function const handleSubmit = async (message: { text: string }) => { if (!channel) return; try { // Send to your backend first const response = await fetch('ENDPOINT_URL/messages', { method: 'POST', headers: { 'Content-Type': 'application/json', }, body: JSON.stringify({ text: message.text, channelId: channel.id, userId: userId, }), }); if (!response.ok) { throw new Error('Failed to process message'); } // Get the processed message from backend const processedMessage = await response.json(); console.log(processedMessage.text.content[0].text); // Send to Stream channel (either original or processed message) return channel.sendMessage({ text: processedMessage.text.content[0].text || message.text, }); } catch (error) { console.error('Error processing message:', error); throw error; } };
This is a pretty simple function. We are taking the message entered by the user and sending it to a /message endpoint on our server. We then process the response to either show the original message or a new message if the message has been moderated.
We then call this function whenever a new message is submitted:
123456789101112return ( <Chat client={client}> <Channel channel={channel}> <Window> <ChannelHeader /> <MessageList /> <MessageInput overrideSubmitHandler={handleSubmit} /> </Window> <Thread /> </Channel> </Chat> );
We use overrideSubmitHandler to intercept our message and send it to our handleSubmit function.
At this point, no moderation is taking place. We need to set up our server endpoint to use an LLM to check each message for profanity.
Using LLMs for Moderation
Our backend server is going to be super simple–a single endpoint that:
- Takes the message from the POST request
- Passes it to Anthropic’s Claude LLM for moderation
- Returns either the message intact or a [Message removed] text instead
Here’s the entire code:
1234567891011121314151617181920212223242526272829303132333435363738394041424344454647484950import express from 'express'; import cors from 'cors'; import Anthropic from '@anthropic-ai/sdk'; import dotenv from 'dotenv'; dotenv.config(); const app = express(); const port = process.env.PORT || 3001; // Initialize Anthropic client const anthropic = new Anthropic({ apiKey: process.env.ANTHROPIC_API_KEY, // Add your API key to .env file }); app.use(cors()); app.use(express.json()); app.post('/messages', async (req, res) => { try { const { text, channelId, userId } = req.body; // Call Claude for content moderation const msg = await anthropic.messages.create({ model: "claude-3-5-sonnet-20241022", max_tokens: 1024, messages: [{ role: "user", content: `If the message is inappropriate, replace it with [Message removed]. If it's fine, return it as-is: "${text}"` }], }); const moderatedText = msg; // Send back the moderated message res.json({ text: moderatedText, channelId, userId, moderated: moderatedText !== text }); } catch (error) { console.error('Error moderating message:', error); res.status(500).json({ error: 'Failed to moderate message' }); } }); app.listen(port, () => { console.log(`Server running on port ${port}`); });
The prompt demonstrates the magic of using an LLM for multilingual content moderation. We don’t have to specify the languages we send—the LLM will handle that automatically.
We’re also not explicitly listing what words we do or don’t want moderated. LLMs, with their language knowledge, understand what words are profane. Let’s revisit the Hungarian conversation above:
The conversation goes:
- Alison: Szia! Jössz ma kávézni?
- Bob: Francba, ma nem tudok, túlóra van 🙁
- Alison: A fenébe... És holnap?
- Bob: Nem, a hülye főnököm egész hétre betáblázott
- Alison: Mi a sz*r... mindig ezt csinálja veled
The Hungarian speakers among you will know that there are some swear words in that ranging from mild (Francba/Damn) to moderate (mi a sz*r/what the sh*t). Bob’s following message he tried to send was, “Ja, egy s*ggfej. R*hadtul elegem van már belőle” which roughly translates as “Yeah, he's an *sshole. I'm f*cking sick of him.”
It is this phrase that AI has deemed “inappropriate.” So, it sends back the [Message removed] tag for us to display to the user. A huge benefit of using LLMs like this instead of a more proscriptive moderation process is that it can shift between languages. Thus, if our chat users are bilingual and suddenly change to writing Korean profanity, the system will also handle that without us having to change our prompt.
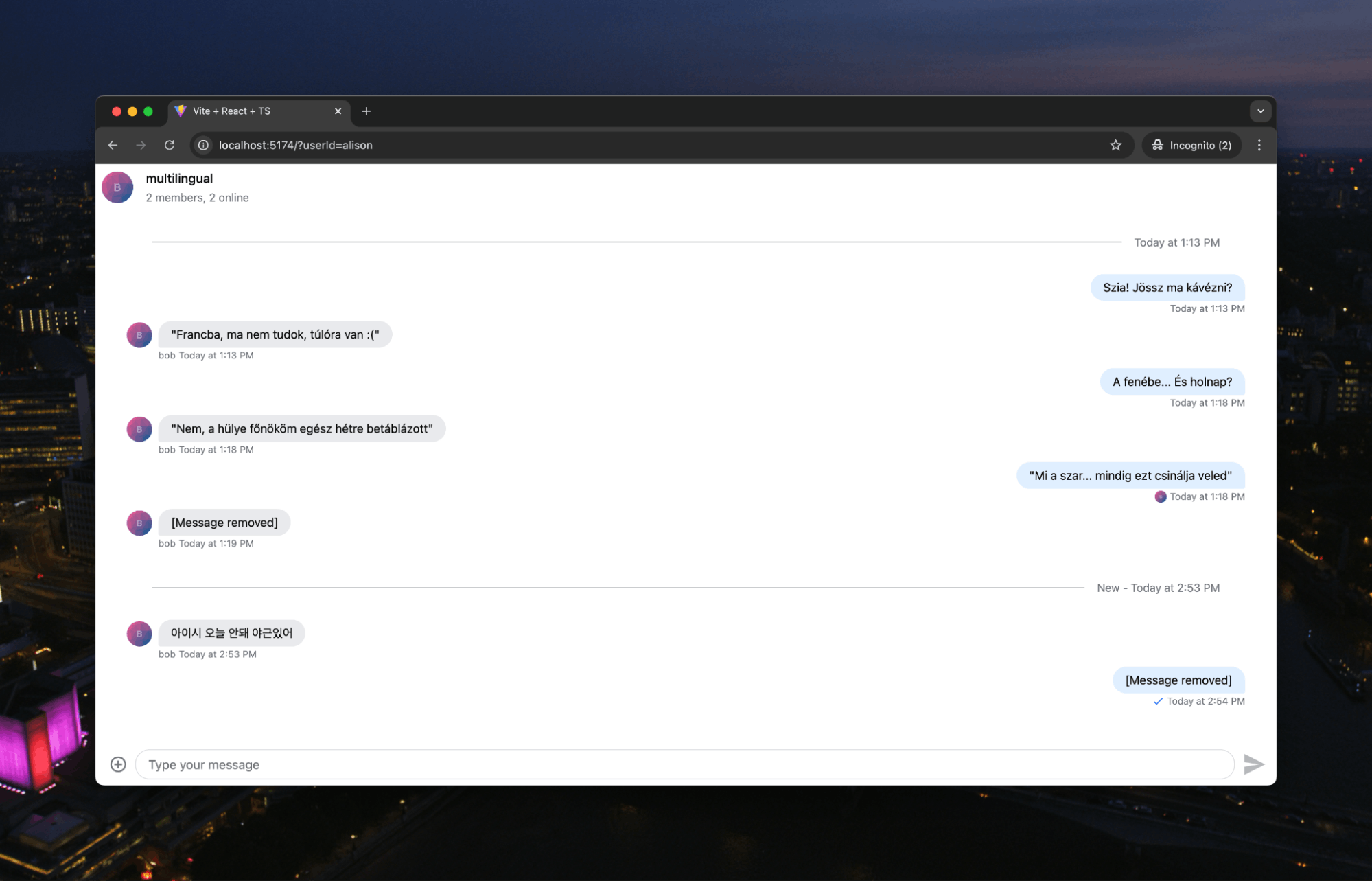
From here, there are some steps you can take to make this system more robust.
- Nuanced prompting. Our prompt allows for moderate swearing. If we wanted to remove all profanity, we might consider more nuanced prompt engineering that tells the LLM to remove all swearing. Alternatively, we might prompt the model to respond with “Mild/Moderate/Strong” labels for any profanity, and then we can decide what to do afterward.
- Escalation. If we choose the latter, we can set up a level of escalation within our application. For instance, mild language might be flagged for review, moderate profanity immediately removed, and strong language leading to a ban for the user.
- Categorization. We’ve only examined profanity here, but that is only a tiny part of what people might post on a chat. Within our prompt, we might set up categorization levels (insult, trolling, racism, harassment) that can be used alongside escalation levels.
This last issue is the biggest issue with building this yourself. You can easily miss a category that needs moderation, resulting in reputational damage when this content hits your platform. That is why using moderation platforms is a better option.
Stream’s Moderation API looks for 40 harms in 30 languages with instant response to allow you to safeguard your platform while also giving your responsible users a great user experience:

It also provides a real-time moderation dashboard with contextual information to your moderators, moderates images and videos, and allows you to build platform-specific moderation. Sign up for your free account and start using Stream Moderation today.