

The OpenAI Agents SDK for Python provides developers with the building blocks to implement two agentic solutions for AI applications. You can create text-generation agents, allowing users to get responses from text prompts. Additionally, you can build voice agents using the SDK. To create your first agent with the OpenAI Agents SDK, get started here.
This tutorial will cover three main goals and aspects of building AI agents.
- 100% local: Use the OpenAI Agents SDK to build agentic workflows that run locally on your computer without compromising business data and private information.
- Use 100+ models: Remove the limitation of using only OpenAI models for the Agents SDK and provide the ability to use open-source models and 100+ LLMs.
- Own tracing: Implement a custom solution for logging and monitoring the performance of your agents.
If these three goals excite you, continue reading to unlock the best way to run the OpenAI Agents SDK entirely locally using the hundreds of AI models you prefer and monitoring their operations with trusted solutions.
Prerequisites
Before we create the demo projects for this article, ensure you have installed the following Python packages and libraries. This is our tech stack.
- OpenAI Agents SDK: Build multi-agents and voice AI apps.
- Ollama: Run large and small language models locally.
- DeepSeek-R1-Distill-Llama-8B: Download a distilled version of DeepSeek R1 from Hugging Face.
- Streamlit and Gradio: Interact with OpenAI agents via an AI chat UI.
- AgentOps: Provides tracing and observation of agents' performances.
- LiteLLM: Gives developers access to 100+ LLMs via Ollama.
Why is Tracing Important in Agentic Workflows?
When building AI applications, tracing operations of the underlying LLMs powering the app helps developers build more reliable solutions. Tracing also assists you in auditing your app to gain insights into logs, errors, and prompt injection attacks.
- Record the agent's events: When an agent runs, you can collect a comprehensive record of events like LLM calls and conversations.
- Evaluate prompts and LLM Switching costs: This helps you to get insights into spending on models.
- Track latency: Easily monitor output generations of an LLM, tool calls, and handoffs, and detect failures.
- Debug and visualize agentic workflows: See interactive visualizations of logs and fine-tune your agents for better performances.
What Problems Are We Solving?
The OpenAI Agents SDK is an excellent choice for building voice and text generation agents. It has more features than even some of the leading agent-building frameworks for Python. However, depending on your use case and business's needs, you may be interested in the following ways to use the SDK.
There are several reasons why developers may want to experiment with their agentic projects locally. Your data may be sensitive, and you want to keep it offline on your machine. You can use any compatible LLM for your agents instead of locking to a specific vendor. Another reason may be the ability to try several open-source models and the free choice of closed ones.
Run Locally
We want to use the Agents SDK but keep our data private and offline without sending them to OpenAI.
Not Limited to Only OpenAI Models
OpenAI recommends using its Responses API to create agents. However, since the responses API supports only OpenAI models, using it means you are vendor-locked into only OpenAI and its family of large language models. Therefore, we will find alternative ways to utilize the Agents SDK entirely but using non-OpenAI models.
Tracing
When building agentic workflows, tracing or agent monitoring is one of the key features to consider and implement in your project. The OpenAI Agents SDK is open-source, but its built-in monitoring system is not. This feature is turned on by default but can be turned off if you do not want your agents to be traced. In this tutorial, we will look at how to implement an alternative open-source tracing option for the agents we build.
Build a File System MCP Agent
Let's create an OpenAI agent to read files and answer questions about them using the File System MCP server on GitHub. The agent will access the contents of your specified files and respond to queries about them. We will use the following text files on GitHub, but feel free to replace them with yours.
Create a Python file, for example, filesystem_mcp_streamlit_agent.py, and fill it out with the following sample code. Here, we interact with the file system agent via a Streamlit UI. Running the code successfully requires installing the OpenAI agents SDK and Streamlit.
123456789101112131415161718192021222324252627282930313233343536373839404142434445464748495051525354555657585960616263646566676869707172737475767778798081828384858687888990919293949596979899100101102103104105106107108109110111112113114115116117118119120121122123124125126127128129130131132133134135136137138139140141142143144145# https://github.com/modelcontextprotocol/servers/tree/main/src/filesystem import streamlit as st import asyncio import os import shutil import tempfile from agents import Agent, Runner, gen_trace_id, trace from agents.mcp import MCPServer, MCPServerStdio # Create a sample file for demonstration if needed def ensure_sample_files(): current_dir = os.path.dirname(os.path.abspath(__file__)) samples_dir = os.path.join(current_dir, "sample_files") # Create the directory if it doesn't exist os.makedirs(samples_dir, exist_ok=True) # Create a sample WWDC predictions file predictions_file = os.path.join(samples_dir, "wwdc25_predictions.md") if not os.path.exists(predictions_file): with open(predictions_file, "w") as f: f.write("# WWDC25 Predictions\n\n") f.write("1. Apple Intelligence features for iPad\n") f.write("2. New Apple Watch with health sensors\n") f.write("3. Vision Pro 2 announcement\n") f.write("4. iOS 18 with advanced customization\n") f.write("5. macOS 15 with AI features\n") # Create a sample WWDC activities file activities_file = os.path.join(samples_dir, "wwdc_activities.txt") if not os.path.exists(activities_file): with open(activities_file, "w") as f: f.write("My favorite WWDC activities:\n\n") f.write("1. Attending sessions\n") f.write("2. Labs with Apple engineers\n") f.write("3. Networking events\n") f.write("4. Exploring new APIs\n") f.write("5. Hands-on demos\n") return samples_dir # Using a separate event loop to run async code in Streamlit class AsyncRunner: @staticmethod def run_async(func, *args, **kwargs): loop = asyncio.new_event_loop() asyncio.set_event_loop(loop) try: return loop.run_until_complete(func(*args, **kwargs)) finally: loop.close() # Function to run a query with error handling def run_agent_query(query): try: # Create a fresh server and agent for each query samples_dir = ensure_sample_files() async def run_query(): server = None try: server = MCPServerStdio( name="Filesystem Server, via npx", params={ "command": "npx", "args": ["-y", "@modelcontextprotocol/server-filesystem", samples_dir], }, ) # Enter the server context mcp_server = await server.__aenter__() agent = Agent( name="Assistant for Content in Files", instructions="Use the tools to read the filesystem and answer questions based on those files.", mcp_servers=[mcp_server], ) trace_id = gen_trace_id() with trace(workflow_name="MCP Filesystem Query", trace_id=trace_id): result = await Runner.run(starting_agent=agent, input=query) return result.final_output, trace_id finally: # Make sure to properly exit the server context if server: await server.__aexit__(None, None, None) return AsyncRunner.run_async(run_query) except Exception as e: st.error(f"Error processing query: {str(e)}") return f"Failed to process query: {str(e)}", None def main(): st.title("File Explorer Assistant") st.write("This app uses an AI agent to read files and answer questions about them.") # Ensure sample files exist ensure_sample_files() # Input area for user queries query = st.text_area("Ask me about the files:", height=100) if st.button("Submit"): if query: with st.spinner("Processing your request..."): result, trace_id = run_agent_query(query) if trace_id: st.write("### Response:") st.write(result) trace_url = f"https://platform.openai.com/traces/trace?trace_id={trace_id}" st.write(f"[View trace]({trace_url})") # Sample queries st.sidebar.header("Sample Queries") if st.sidebar.button("List all files"): with st.spinner("Processing..."): result, trace_id = run_agent_query("Read the files and list them.") if trace_id: st.write("### Files in the system:") st.write(result) if st.sidebar.button("WWDC Activities"): with st.spinner("Processing..."): result, trace_id = run_agent_query("What are my favorite WWDC activities?") if trace_id: st.write("### WWDC Activities:") st.write(result) if st.sidebar.button("WWDC25 Predictions"): with st.spinner("Processing..."): result, trace_id = run_agent_query("Look at my wwdc25 predictions. List the predictions that are most likely to be true.") if trace_id: st.write("### WWDC25 Predictions Analysis:") st.write(result) if __name__ == "__main__": # Let's make sure the user has npx installed if not shutil.which("npx"): st.error("npx is not installed. Please install it with `npm install -g npx`.") else: main()
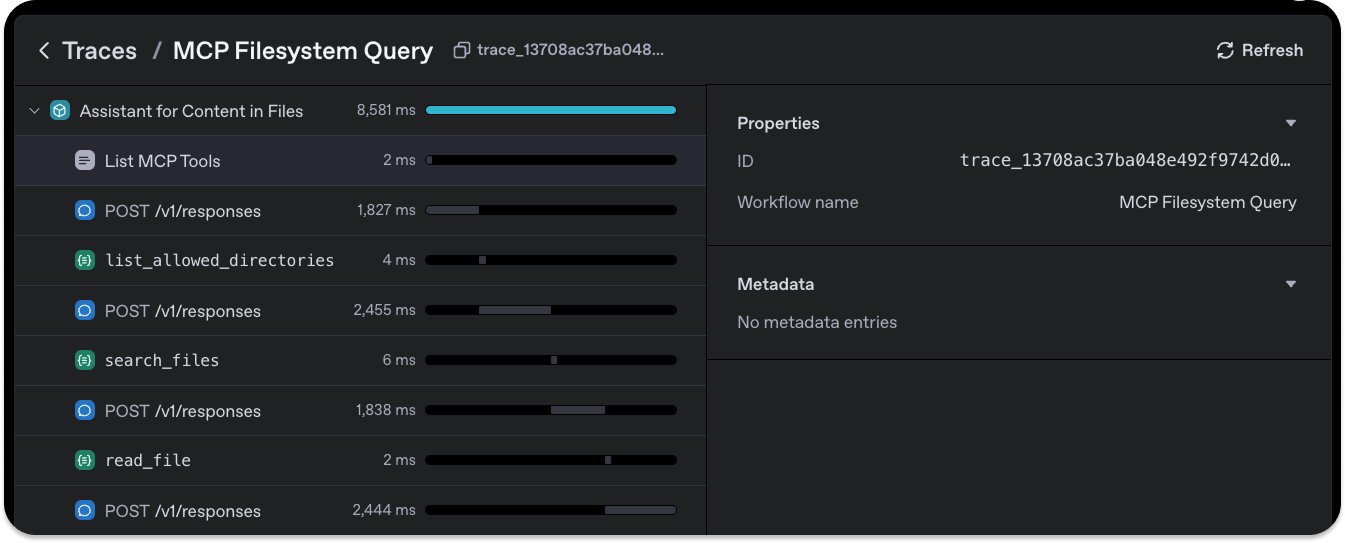
The output of the sample code will be similar to this image when you run it.

In the image preview above, clicking View trace will take you to your OpenAI dashboard, where you can view logs about the agent, such as the list of tools, responses, and more.
Configure Your Local Environment
To run any agent or even the previous file system MCP locally, we can use a tool like Ollama and supported AI models such as DeepSeek R1, Phi-4, etc. Check out the Prerequisites section at the beginning of the article to download and install Ollama and a distilled GGUF version of DeepSeek R1. To ensure Ollma and the DeepSeek R1 model will operate successfully, run this command in your Terminal.
ollama run deepseek-r1
You will be given an output in the Terminal similar to the following to initiate a new chat with the model.
>>> Send a message (/? for help)
What we did was just for testing purposes. Let's continue from the next section by converting our previous OpenAI file system MCP agent into a local one.
Ollama-Supported Models and Streamlit UI Example
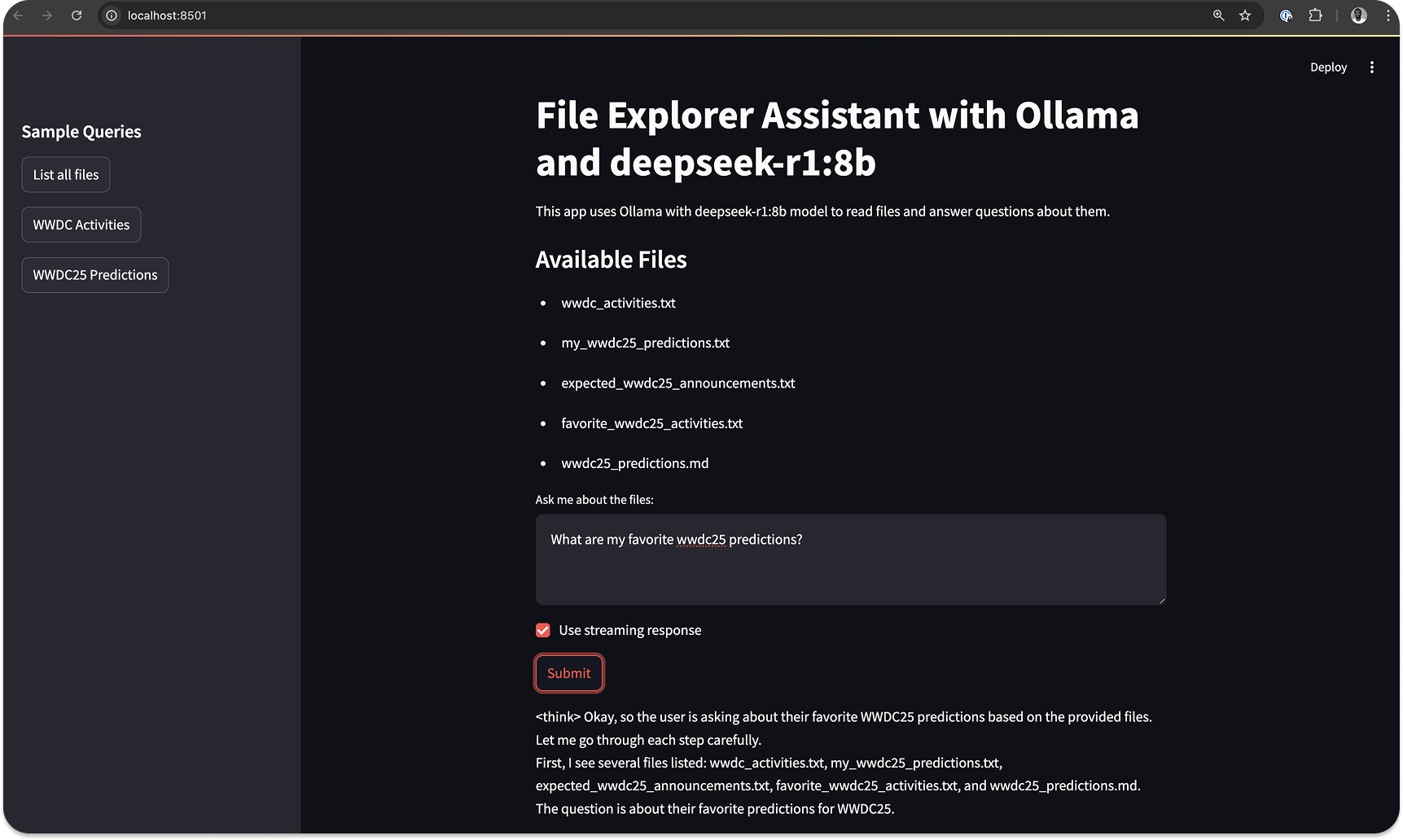
In this section, we modify the previous section’s code to use the OpenAI SDK but run the agent locally using a non-OpenAI model. To run the file system MCP agent with an Ollama-supported model (DeepSeek R1), create a new Python file and copy the content of local_openai_filesystem_mcp_agent.py from GitHub to fill out yours.
The part of the sample code worth mentioning is implementing the OpenAI agent to run locally via Ollama. The code snippet below can initialize any open-source AI model Ollama supports. To serve the model through Ollama, you specify the name of the open-source model and the base URL
base_url="http://localhost:11434/v1".
12345# Initialize the model and agent local_model = OpenAIChatCompletionsModel( model="deepseek-r1:8b", openai_client=AsyncOpenAI(base_url="http://localhost:11434/v1") )
After downloading and running the complete code from GitHub, you should see an output similar to this preview.
Our example local OpenAI agent works excellently with all the models Ollama provides. However, you may need more model support options for large-scale or enterprise AI applications than those available on Ollama. Since we use an open-source model, DeepSeek R1, the agent's operations won't be traced on your OpenAI dashboard for this example. In the next section, we will implement another tech stack to run the agent with any model provider.
Ollama + Gradio + LiteLLM: Access 100+ LLMs
This section will build an OpenAI agent in Python that can call 100+ APIs and LLMs. We will implement the example with the following tech stack to make it possible to work with any model provider.
- OpenAI Agents SDK: Provides the underlying agent-building API.
- Ollama: To offer support in running any selected model locally.
- LiteLLM: Enables the app to access 100+ models.
- Gradio: To build a UI to chat with the OpenAI agent.
The main objective is to extend the demo agent we created to make it more accessible to any model. Let's start by installing the following.
pip install gradio litellm
Then, launch your favorite IDE, create a new Python file, and use the following sample code for its content.
Note: Why create the UI for this example using Gradio instead of Streamlit? Gradio has seamless support for LiteLLM and Ollama, making the integrations much more manageable.
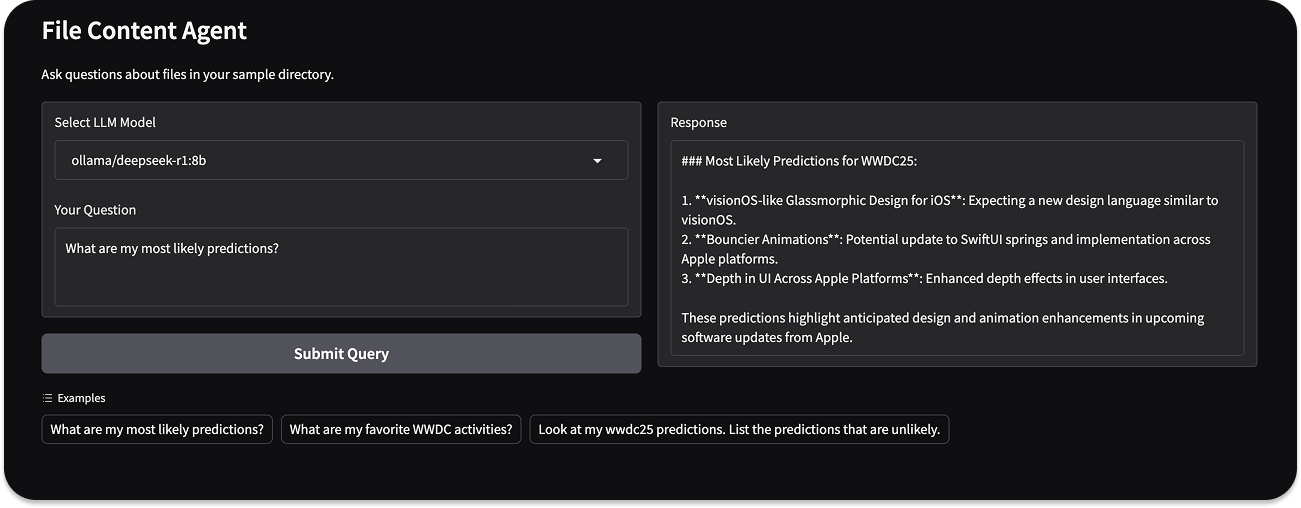
123456789101112131415161718192021222324252627282930313233343536373839404142434445464748495051525354555657585960616263646566676869707172737475767778798081828384858687888990919293949596979899100101102103104105106107108109110111112113114115116117118119120121122123124# https://github.com/modelcontextprotocol/servers/tree/main/src/filesystem import asyncio import os import shutil import gradio as gr import litellm from agents import Agent, Runner from agents.mcp import MCPServer, MCPServerStdio # Configure litellm to use Ollama litellm.set_verbose = True # List of available models - can be expanded AVAILABLE_MODELS = [ "ollama/deepseek-r1:8b", # Default model "ollama/llama3:8b", "ollama/mistral:7b", "ollama/gemma:7b", "ollama/phi3:mini", # Add other providers if needed "openai/gpt-3.5-turbo", "anthropic/claude-3-haiku" ] DEFAULT_MODEL = "ollama/deepseek-r1:8b" async def process_query(query, mcp_server, model_name): # Configure LiteLLM to use the selected model litellm.model = model_name # Create the agent agent = Agent( name="Assistant for Content in Files", instructions="Use the tools to read the filesystem and answer questions based on those files.", mcp_servers=[mcp_server], ) # Run the agent result = await Runner.run(starting_agent=agent, input=query) return result.final_output async def handle_query(query, model_name): current_dir = os.path.dirname(os.path.abspath(__file__)) samples_dir = os.path.join(current_dir, "sample_files") async with MCPServerStdio( name="Filesystem Server, via npx", params={ "command": "npx", "args": ["-y", "@modelcontextprotocol/server-filesystem", samples_dir], }, ) as server: output = await process_query(query, server, model_name) return output def gradio_query(query, model_name): if not shutil.which("npx"): return "Error: npx is not installed. Please install it with `npm install -g npx`." # Check if Ollama is selected but not running if model_name.startswith("ollama/"): try: # Simple check to see if Ollama is accessible asyncio.run(litellm.acompletion( model=model_name, messages=[{"role": "user", "content": "test"}], max_tokens=1 )) except Exception as e: return f"Error: Ollama is not running or model {model_name} is not available. Please start Ollama first." try: result = asyncio.run(handle_query(query, model_name)) return result except Exception as e: return f"Error: {str(e)}" def create_demo(): with gr.Blocks() as demo: gr.Markdown("# File Content Agent") gr.Markdown("Ask questions about files in your sample directory.") with gr.Row(): with gr.Column(): model_selector = gr.Dropdown( choices=AVAILABLE_MODELS, value=DEFAULT_MODEL, label="Select LLM Model" ) query_input = gr.Textbox( label="Your Question", placeholder="e.g., Read the files and list them.", lines=3 ) submit_btn = gr.Button("Submit Query") with gr.Column(): output = gr.Textbox(label="Response", lines=10) # Add example queries example_queries = [ "What are my most likely predictions?", "What are my favorite WWDC activities?", "Look at my wwdc25 predictions. List the predictions that are unlikely." ] gr.Examples( examples=example_queries, inputs=query_input ) submit_btn.click( fn=gradio_query, inputs=[query_input, model_selector], outputs=output ) return demo if __name__ == "__main__": # Create and launch the Gradio app demo = create_demo() demo.launch()
Running the app will display a UI similar to the image at the beginning of this section. One unique feature of this example is that we can run the agent with closed, open-source, large, and small language models from any provider. Thanks 🙏 to LiteLLM and Ollama, you can access and add your preferred models from OpenAI, Anthropic, Gemini, Azure, BedRock, DeepSeek, Meta AI, xAI, Mistral, etc.
Implement Your Agents’ Logging System With AgentOps
For an AI agent to work reliably, robust tracing and monitoring of the performance of the underlying LLM must be implemented. Several solutions are available to integrate and monitor your AI apps and agents. You can, for example, add Literal AI to your agents to evaluate and manage prompts with beautiful visual representations.
However, the OpenAI Agents SDK provides support for selected tracing solutions. You can use any monitoring services OpenAI recommends, but we will use AgentOps for this section. AgentsOps AI provides developers the tools to debug, trace, and deploy AI applications securely and reliably.
Let's use it to trace our local OpenAI agent.
First, install the AgentOps Python package with this command.
pip install agentops
Next, modify the code in the previous section to implement AgentOps for tracing the local OpenAI agent. We create the tracing implementation using this sample code.
123456789101112131415161718192021222324252627282930313233343536373839404142434445464748495051525354555657585960616263646566676869707172737475767778798081828384858687888990919293949596979899100101102103104105106107108109110111112113114115116117118119120121122123124125126127128129130131132133134135136137138139140141142143144145146147148149150# https://github.com/modelcontextprotocol/servers/tree/main/src/filesystem import asyncio import os import shutil import gradio as gr import litellm import agentops from agents import Agent, Runner from agents.mcp import MCPServer, MCPServerStdio # Initialize AgentOps - configure with your API key if needed # agentops.configure(api_key="your_api_key_here") agentops.init() # Configure litellm logging using environment variable os.environ['LITELLM_LOG'] = 'DEBUG' # List of available models - can be expanded AVAILABLE_MODELS = [ "ollama/deepseek-r1:8b", # Default model "ollama/llama3:8b", "ollama/mistral:7b", "ollama/gemma:7b", "ollama/phi3:mini", # Add other providers if needed "openai/gpt-4o-mini", "anthropic/claude-3-haiku" ] DEFAULT_MODEL = "ollama/deepseek-r1:8b" async def process_query(query, mcp_server, model_name): # Configure LiteLLM to use the selected model litellm.model = model_name # Create the agent agent = Agent( name="Assistant for Content in Files", instructions="Use the tools to read the filesystem and answer questions based on those files.", mcp_servers=[mcp_server], ) # Start tracking a session with tags session = agentops.start_session(tags={ "model": model_name, "query_type": "file_content", }) try: # Run the agent result = await Runner.run(starting_agent=agent, input=query) # End the session successfully agentops.end_session(session) return result.final_output except Exception as e: # End the session with error agentops.end_session(session, error=str(e)) raise async def handle_query(query, model_name): current_dir = os.path.dirname(os.path.abspath(__file__)) samples_dir = os.path.join(current_dir, "sample_files") try: async with MCPServerStdio( name="Filesystem Server, via npx", params={ "command": "npx", "args": ["-y", "@modelcontextprotocol/server-filesystem", samples_dir], }, ) as server: output = await process_query(query, server, model_name) return output except Exception as e: raise def gradio_query(query, model_name): if not shutil.which("npx"): return "Error: npx is not installed. Please install it with `npm install -g npx`." # Check if Ollama is selected but not running if model_name.startswith("ollama/"): try: # Simple check to see if Ollama is accessible asyncio.run(litellm.acompletion( model=model_name, messages=[{"role": "user", "content": "test"}], max_tokens=1 )) except Exception as e: return f"Error: Ollama is not running or model {model_name} is not available. Please start Ollama first." try: result = asyncio.run(handle_query(query, model_name)) return result except Exception as e: return f"Error: {str(e)}" def create_demo(): with gr.Blocks() as demo: gr.Markdown("# File Content Agent") gr.Markdown("Ask questions about files in your sample directory.") with gr.Row(): with gr.Column(): model_selector = gr.Dropdown( choices=AVAILABLE_MODELS, value=DEFAULT_MODEL, label="Select LLM Model" ) query_input = gr.Textbox( label="Your Question", placeholder="e.g., Read the files and list them.", lines=3 ) submit_btn = gr.Button("Submit Query") with gr.Column(): output = gr.Textbox(label="Response", lines=10) # Add example queries example_queries = [ "What are my most likely predictions?", "What are my favorite WWDC activities?", "Look at my wwdc25 predictions. List the predictions that are unlikely." ] gr.Examples( examples=example_queries, inputs=query_input ) submit_btn.click( fn=gradio_query, inputs=[query_input, model_selector], outputs=output ) return demo if __name__ == "__main__": # Create and launch the Gradio app demo = create_demo() demo.launch() # End all sessions when the application exits agentops.end_all_sessions()
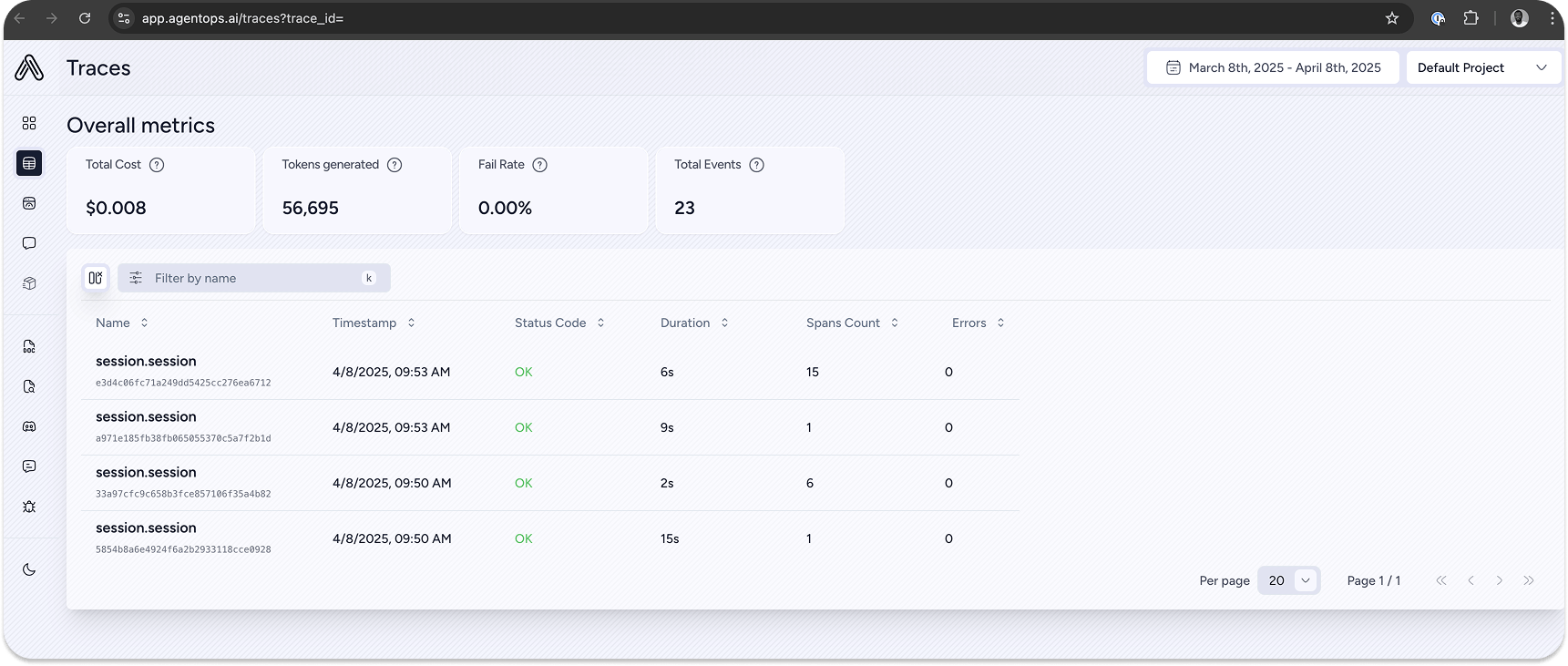
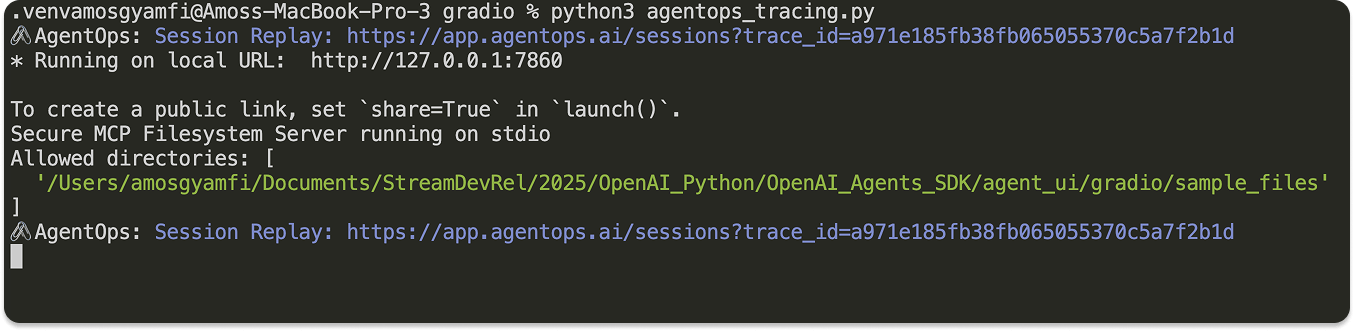
The code's functionality remains the same as in the previous section, except for the tracing feature. When you run the code, you will receive a Session Replay link to view the agent's traces in your AgentOps dashboard.
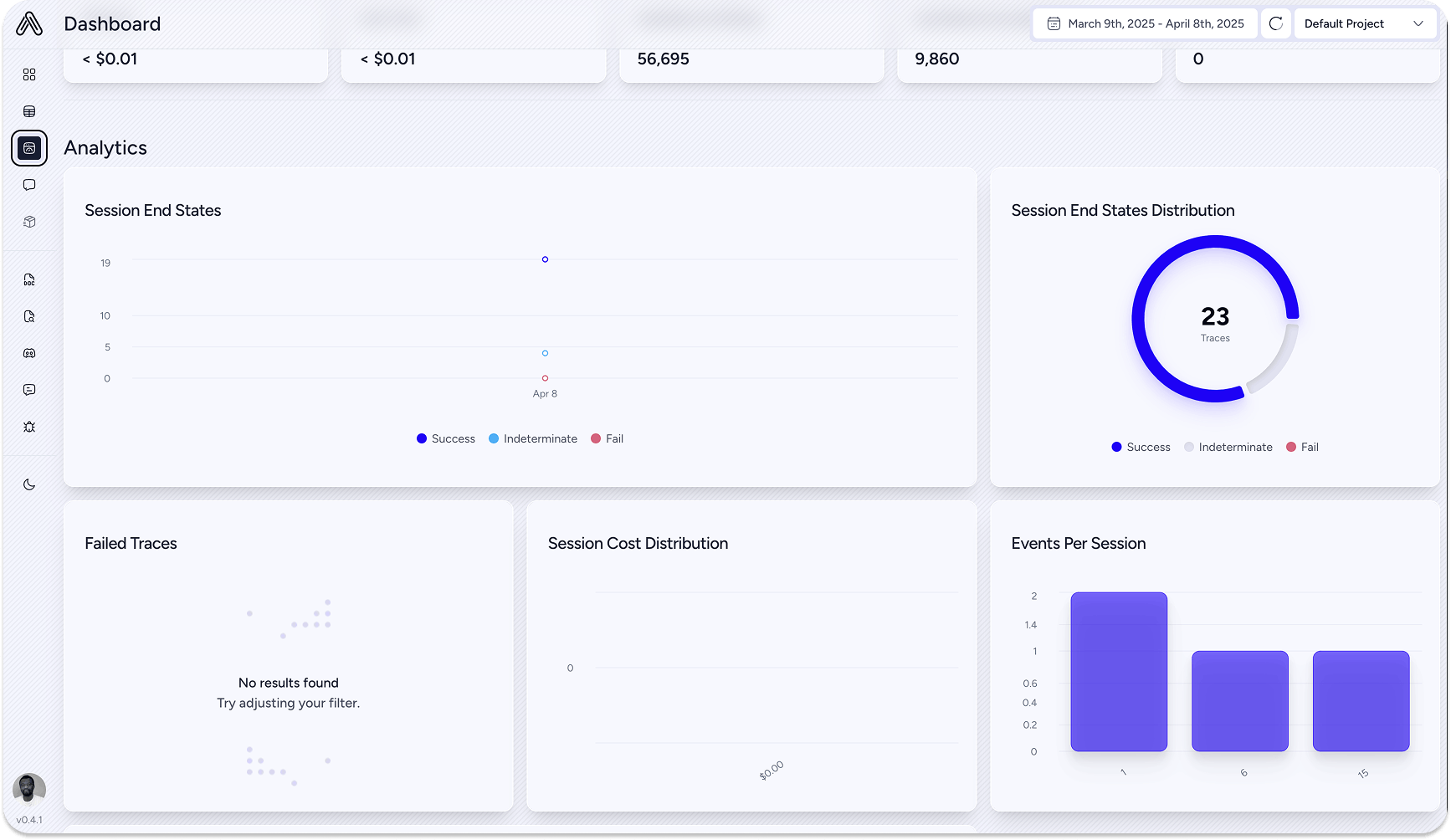
Clicking the link will display the agent's sessions and overall metrics on the dashboard.
Congratulations! 👏 You can now create local voice and AI apps with the OpenAI Agents SDK by integrating them with other technologies, such as Ollama, LiteLLM, AgentOps, etc.
Where to Go From Here
In this article, we examined building and running OpenAI agents with local toolkits that support free choices of LLM providers and implement custom AI model tracing. We covered only the offline aspect of using the Agents SDK. However, several features can be added to your AI applications, such as voice agents, providing context to models, and more.